Rust-Python FFI

Writing a rust library that is usable in multiple languages is not easy...
This blogpost recollects things I have encountered while building wonnx and dora-rs. I am going to use Rust-Python FFI through pyo3 as an example. You can then extrapolate those issues to other languages FFI.
Foreign Function Interface
A foreign function interface (FFI) is an interface used to share data from different languages.
By default, python might not know what a Rust u16 is, so an interface is needed to make the two languages communicate.

Image from WebAssembly Interface Types: Interoperate with All the Things!
Building interfaces is not easy. Most of the time, we have to use the C-ABI to build our FFI as it is the common denominator between languages.
Thankfully, there are FFI libraries that create interfaces for us and we can just focus on the important stuff such as the logic, algorithm, and so on.
However, those FFI libraries might have limitations. This is what we're going to discuss.
One example of such FFI library is pyo3. pyo3 is one of the most used Rust-Python binding and creates FFIs for you. All we have to do is wrap our function with a #[pyfunction] and that will make it usable in Python.
Interfacing Arrays
In this blog post, I'm going to build a toy Rust-Python project with pyo3 to illustrate the issues I have faced.
You can try this blogpost at home by forking the blogpost repository.
If you want to start from scratch, you can create a new project with:
mkdir blogpost_ffi
maturin init # pyo3
The default project will looks like this:
use pyo3::prelude::*;
/// Formats the sum of two numbers as string.
#[pyfunction]
fn sum_as_string(a: usize, b: usize) -> PyResult<String> {
Ok((a + b).to_string())
}
/// A Python module implemented in Rust. The name of this function must match
/// the `lib.name` setting in the `Cargo.toml`, else Python will not be able to
/// import the module.
#[pymodule]
fn string_sum(_py: Python<'_>, m: &PyModule) -> PyResult<()> {
m.add_function(wrap_pyfunction!(sum_as_string, m)?)?;
Ok(())
}
We can call the function as follows:
maturin develop
python -c "import blogpost_ffi; print(blogpost_ffi.sum_as_string(1,1))"
# Return: "2"
In the above example, pyo3 is going to create FFIs to make Python integer interpretable as a Rust usize without additional work.
However, automatically interpreted types might not be the most optimized implementation.
Implementation 1: Default
Let's imagine that, we want to play with arrays, we want to receive an array input and return an array output between Rust and Python. A default inplementation, would look like this:
#[pyfunction]
fn create_list(a: Vec<&PyAny>) -> PyResult<Vec<&PyAny>> {
Ok(a)
}
#[pymodule]
fn blogpost_ffi(_py: Python, m: &PyModule) -> PyResult<()> {
m.add_function(wrap_pyfunction!(sum_as_string, m)?)?;
m.add_function(wrap_pyfunction!(create_list, m)?)?;
Ok(())
}
> Calling create_list for a very large list like: value = [1] * 100_000_000 is going to return in 2.27s 🚜
That's quite slow... The reason being is that this list is going to be interpret one element at a time in a loop. We can do better by trying to use all elements at the same time.
Check test_script.py for details on how the function is called.
Implementation 2: PyBytes
Let's imagine that our array is a C-contiguous array that can be represented as a PyBytes. The code can be optimized by casting the inputs and output as a PyBytes:
#[pyfunction]
fn create_list_bytes<'a>(py: Python<'a>, a: &'a PyBytes) -> PyResult<&'a PyBytes> {
let s = a.as_bytes();
let output = PyBytes::new_with(py, s.len(), |bytes| {
bytes.copy_from_slice(s);
Ok(())
})?;
Ok(output)
}
> For the same list input, create_list_bytes returns in 78 milliseconds. That's 30x better 🐎
The speedup comes from the possibility to copy the memory range instead of iterating each element and to read without copying.
Now the issue is that:
PyBytesis only available in Python meaning that if we plan to have other languages, we will have to replicate this for each language.PyBytesmight also probably need to be reconverted into other useful types.PyBytesneeds a copy to be created.
We can try to solve this with Apache Arrow.
Implementation 3: Apache Arrow
Apache Arrow is a universal memory format available in many languages.
The same function in arrow would look like this:
#[pyfunction]
fn create_list_arrow(py: Python, a: &PyAny) -> PyResult<Py<PyAny>> {
let arraydata = arrow::array::ArrayData::from_pyarrow(a).unwrap();
let buffer = arraydata.buffers()[0].as_slice();
let len = buffer.len();
// Zero Copy Buffer reference counted
let arc_s = Arc::new(buffer.to_vec());
let ptr = NonNull::new(arc_s.as_ptr() as *mut _).unwrap();
let raw_buffer = unsafe { arrow::buffer::Buffer::from_custom_allocation(ptr, len, arc_s) };
let output = arrow::array::ArrayData::try_new(
arrow::datatypes::DataType::UInt8,
len,
None,
0,
vec![raw_buffer],
vec![],
)
.unwrap();
output.to_pyarrow(py)
}
> Same list returns in 33 milliseconds . That's 2x better than PyBytes 🐎🐎
This is due to having zero copy when sending back the result. The zero-copying is safe because we are reference-counting the array. The array will be deallocating once all reference has been removed.
The benefits of arrow is:
- to make zero-copy achievable, scaling better with bigger data.
- being reusable in other languages. We only have to replace the last line of the function with the export to the other languages.
- having many types description including
List,MappingandStruct. - being directly usable in
numpy,pandas, andpytorchwith zero-copy transmutation.
Debugging
Dealing with efficient Interface is not the only challenge of bridging multiple languages. We also have to deal with cross-language debugging.
.unwrap()
Our current implementation uses .unwrap(). However, this will panic the whole Python process if there is an error.
> Example error:
thread '<unnamed>' panicked at 'called `Result::unwrap()` on an `Err` value: PyErr { type: <class 'TypeError'>, value: TypeError('Expected instance of pyarrow.lib.Array, got builtins.int'), traceback: None }', src/lib.rs:45:62
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Traceback (most recent call last):
File "/home/peter/Documents/work/blogpost_ffi/test_script.py", line 79, in <module>
array = blogpost_ffi.create_list_arrow(1)
pyo3_runtime.PanicException: called `Result::unwrap()` on an `Err` value: PyErr { type: <class 'TypeError'>, value: TypeError('Expected instance of pyarrow.lib.Array, got builtins.int'), traceback: None }
eyre
Eyre is an easy idiomatic error handling library for Rust applications. We can use eyre by wrapping our pyo3 project with the pyo3/eyre feature flag, to replace all our .unwrap() with a .context("our context")?. This will transform unrecoverable errors into recoverable Python errors while giving details about our errors.
> Same error as above but with eyre which gives a better looking error message:
Could not convert arrow data
Caused by:
TypeError: Expected instance of pyarrow.lib.Array, got builtins.int
Location:
src/lib.rs:75:50
Implementation details:
#[pyfunction]
fn create_list_arrow_eyre(py: Python, a: &PyAny) -> Result<Py<PyAny>> {
let arraydata =
arrow::array::ArrayData::from_pyarrow(a).context("Could not convert arrow data")?;
let buffer = arraydata.buffers()[0].as_slice();
let len = buffer.len();
// Zero Copy Buffer reference counted
let arc_s = Arc::new(buffer.to_vec());
let ptr = NonNull::new(arc_s.as_ptr() as *mut _).context("Could not create pointer")?;
let raw_buffer = unsafe { arrow::buffer::Buffer::from_custom_allocation(ptr, len, arc_s) };
let output = arrow::array::ArrayData::try_new(
arrow::datatypes::DataType::UInt8,
len,
None,
0,
vec![raw_buffer],
vec![],
)
.context("could not create arrow arraydata")?;
output
.to_pyarrow(py)
.context("Could not convert to pyarrow")
}
Python traceback with eyre
I will mention that you might lose the Python traceback error when calling Python code from a Rust code.
I recommend using the following custom traceback method to have a descriptive error:
#[pyfunction]
fn call_func_eyre(py: Python, func: Py<PyAny>) -> Result<()> {
let _call_python = func.call0(py).context("function called failed")?;
Ok(())
}
fn traceback(err: pyo3::PyErr) -> eyre::Report {
let traceback = Python::with_gil(|py| err.traceback(py).and_then(|t| t.format().ok()));
if let Some(traceback) = traceback {
eyre::eyre!("{traceback}\n{err}")
} else {
eyre::eyre!("{err}")
}
}
#[pyfunction]
fn call_func_eyre_traceback(py: Python, func: Py<PyAny>) -> Result<()> {
let _call_python = func
.call0(py)
.map_err(traceback) // this will gives python traceback.
.context("function called failed")?;
Ok(())
}
> Example error with no custom traceback:
---Eyre no traceback---
eyre no traceback says: function called failed
Caused by:
AssertionError: I have no idea what is wrong
Location:
src/lib.rs:89:39
------
> Better errors with custom traceback:
---Eyre traceback---
eyre traceback says: function called failed
Caused by:
Traceback (most recent call last):
File "/home/peter/Documents/work/blogpost_ffi/test_script.py", line 96, in abc
assert False, "I have no idea what is wrong"
AssertionError: I have no idea what is wrong
Location:
src/lib.rs:96:9
------
With the traceback, we can quickly identify the root error.
Memory management
Let's take another example, and imagine that we need to create arrays within a loop:
/// Unbounded memory growth
#[pyfunction]
fn unbounded_memory_growth(py: Python) -> Result<()> {
for _ in 0..10 {
let a: Vec<u8> = vec![0; 40_000_000];
let _ = PyBytes::new(py, &a);`
std::thread::sleep(Duration::from_secs(1));
}
Ok(())
> Calling this function will consume 440MB of memory. 👎
What happened is that pyo3 memory model keeps all Python variables in memory until the GIL is released.
Therefore, if we create variables in a pyfunction loop, all temporary variables are going to be kept until the GIL is released.
This is due to pyfunction locking the GIL by default.
By understanding the GIL-based memory model, we can use a scoped GIL to have the expected behaviour:
#[pyfunction]
fn bounded_memory_growth(py: Python) -> Result<()> {
py.allow_threads(|| {
for _ in 0..10 {
Python::with_gil(|py| {
let a: Vec<u8> = vec![0; 40_000_000];
let _bytes = PyBytes::new(py, &a);
std::thread::sleep(Duration::from_secs(1));
});
}
});
// or
for _ in 0..10 {
let pool = unsafe { py.new_pool() };
let py = pool.python();
let a: Vec<u8> = vec![0; 40_000_000];
let _bytes = PyBytes::new(py, &a);
std::thread::sleep(Duration::from_secs(1));
}
Ok(())
}
> Calling this function will consume 80MB of memory. :thumbsup:
Race condition
Let's take another example, and imagine that we need to process data in different threads:
/// Function GIL Lock
#[pyfunction]
fn gil_lock() {
let start_time = Instant::now();
std::thread::spawn(move || {
Python::with_gil(|py| println!("This threaded print was printed after {:#?}", &start_time.elapsed()));
});
std::thread::sleep(Duration::from_secs(10));
}
> This threaded print was printed after 10.0s. 😢
When using Python with pyo3, we have to make sure to know exactly when the GIL is locked or unlocked to avoid race conditions.
In the example above, the issue is that by default pyo3 is going to lock the GIL in the main function thread, therefore blocking the spawned thread that is waiting for the GIL.
If we use the GIL in the main function thread or release the GIL in the main function thread, there is no issue.
/// No gil lock
#[pyfunction]
fn gil_unlock() {
let start_time = Instant::now();
std::thread::spawn(move || {
std::thread::sleep(Duration::from_secs(10));
});
Python::with_gil(|py| println!("1. This was printed after {:#?}", &start_time.elapsed()));
// or
let start_time = Instant::now();
std::thread::spawn(move || {
Python::with_gil(|py| println!("2. This was printed after {:#?}", &start_time.elapsed()));
});
Python::with_gil(|py| {
py.allow_threads(|| {
std::thread::sleep(Duration::from_secs(10));
})
});
}
> "1" was printed after 32µs and "2" was printed after 80µs, so there was no race condition. 😄
Tracing
As we can see, being able to measure the time spent when interfacing can be very valuable to identify bottlenecks.
But measuring the time spent manually as we did before can be tedious.
What we can do is use a tracing library to do it for us. Opentelemetry can help us build a distributed observable system capable of bridging multiple languages. Opentelemetry can be used for tracing, metrics and logs.
For example, if we add:
/// No gil lock
#[pyfunction]
fn global_tracing(py: Python, func: Py<PyAny>) {
// global::set_text_map_propagator(opentelemetry_jaeger::Propagator::new());
global::set_text_map_propagator(TraceContextPropagator::new());
// Connect to Jaeger Opentelemetry endpoint
// Start a new endpoint with:
// docker run -d -p6831:6831/udp -p6832:6832/udp -p16686:16686 jaegertracing/all-in-one:latest
let _tracer = opentelemetry_jaeger::new_agent_pipeline()
.with_endpoint("172.17.0.1:6831")
.with_service_name("rust_ffi")
.install_simple()
.unwrap();
let tracer = global::tracer("test");
// Parent Trace, first trace
let _ = tracer.in_span("parent_python_work", |cx| -> Result<()> {
std::thread::sleep(Duration::from_secs(1));
let mut map = HashMap::new();
global::get_text_map_propagator(|propagator| propagator.inject_context(&cx, &mut map));
let output = func
.call1(py, (map,))
.map_err(traceback)
.context("function called failed")?;
let out_map: HashMap<String, String> = output.extract(py).unwrap();
let out_context = global::get_text_map_propagator(|prop| prop.extract(&out_map));
std::thread::sleep(Duration::from_secs(1));
let _span = tracer.start_with_context("after_python_work", &out_context); // third trace
Ok(())
});
}
And the following, in the Python code:
def abc(cx):
propagator = TraceContextTextMapPropagator()
context = propagator.extract(carrier=cx)
with tracing.tracer.start_as_current_span(
name="Python_span", context=context
) as child_span:
child_span.add_event("in Python!")
output = {}
tracing.propagator.inject(output)
time.sleep(2)
return output
We will get the following traces:
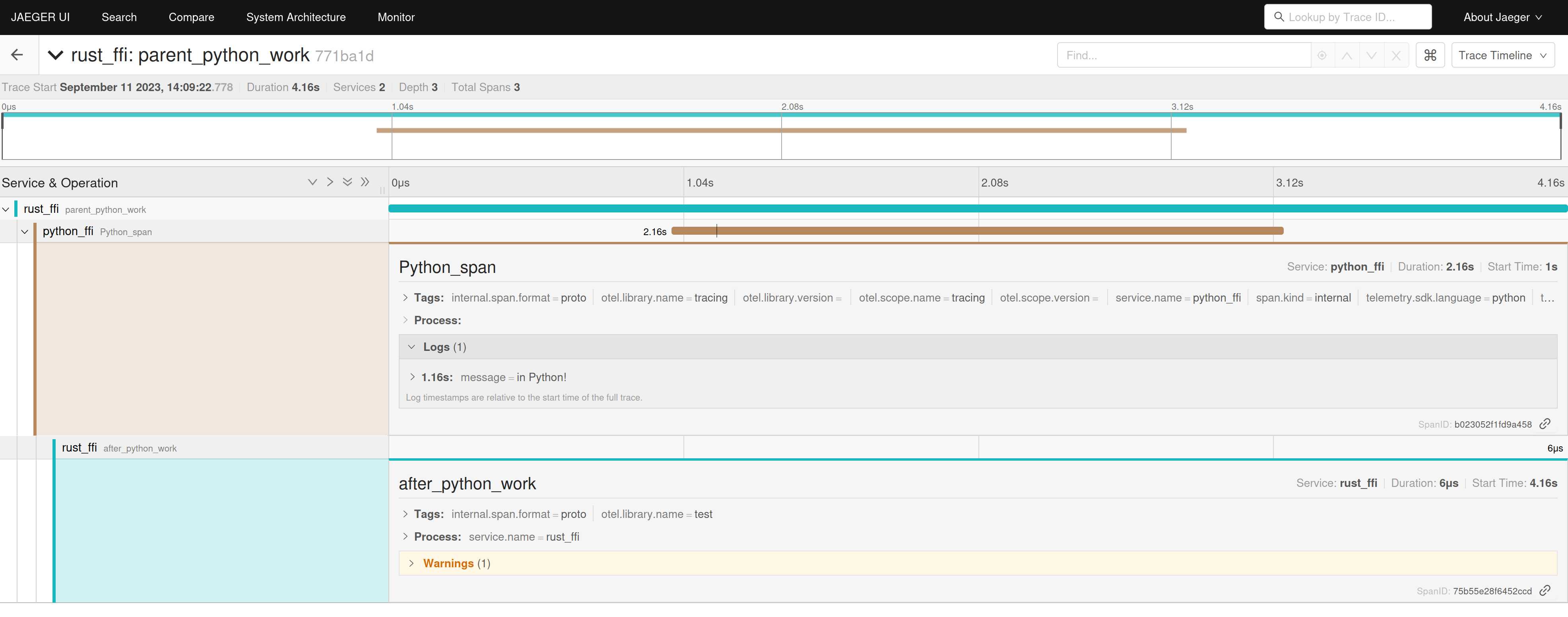
Using this we can measure the time spent when interfacing languages, identify lock issues, and with the combination of logs and metrics, reduce the complexity of multi-language libraries.
dora-rs
Hopefully, this small blog post should help you identify FFI issues.
All optimization above have already been implemented within dora-rs that lets you build fast and simple dataflows using Rust, Python, C and C++.
You're very welcome to check out dora-rs if bridging languages in a dataflow is your usecase.
We just recently opened a Discord and you can reach out there for literally any question, even just for a quick chat: https://discord.gg/DXJ6edAtym
I'm also going to present this FFI work at GOSIM Workshop in Shanghai on the 23rd of Sept 2023!
For more info on dora-rs:
- Github: https://github.com/dora-rs/dora
- Website: https://www.dora-rs.ai/
- Discord: https://discord.gg/XqhQaN8P